It’s time for another dive into how Tesla intends to implement FSD. Once again, a shout out to SETI Park over on X for their excellent coverage of Tesla’s patents.
This time, it's about how Tesla is building a “universal translator” for AI, allowing its FSD or other neural networks to adapt seamlessly to different hardware platforms.
That translating layer can allow a complex neural net—like FSD—to run on pretty much any platform that meets its minimum requirements. This will drastically help reduce training time, adapt to platform-specific constraints, decide faster, and learn faster.
We’ll break down the key points of the patents and make them as understandable as possible. This new patent is likely how Tesla will implement FSD on non-Tesla vehicles, Optimus, and other devices.
Decision Making
Imagine a neural network as a decision-making machine. But building one also requires making a series of decisions about its structure and data processing methods. Think of it like choosing the right ingredients and cooking techniques for a complex recipe. These choices, called "decision points," play a crucial role in how well the neural network performs on a given hardware platform.
To make these decisions automatically, Tesla has developed a system that acts like a "run-while-training" neural net. This ingenious system analyzes the hardware's capabilities and adapts the neural network on the fly, ensuring optimal performance regardless of the platform.
Constraints
Every hardware platform has its limitations – processing power, memory capacity, supported instructions, and so on. These limitations act as "constraints" that dictate how the neural network can be configured. Think of it like trying to bake a cake in a kitchen with a small oven and limited counter space. You need to adjust your recipe and techniques to fit the constraints of your kitchen or tools.
Tesla's system automatically identifies these constraints, ensuring the neural network can operate within the boundaries of the hardware. This means FSD could potentially be transferred from one vehicle to another and adapt quickly to the new environment.
Let’s break down some of the key decision points and constraints involved:
Data Layout: Neural networks process vast amounts of data. How this data is organized in memory (the "data layout") significantly impacts performance. Different hardware platforms may favor different layouts. For example, some might be more efficient with data organized in the NCHW format (batch, channels, height, width), while others might prefer NHWC (batch, height, width, channels). Tesla's system automatically selects the optimal layout for the target hardware.
Algorithm Selection: Many algorithms can be used for operations within a neural network, such as convolution, which is essential for image processing. Some algorithms, like the Winograd convolution, are faster but may require specific hardware support. Others, like Fast Fourier Transform (FFT) convolution, are more versatile but might be slower. Tesla's system intelligently chooses the best algorithm based on the hardware's capabilities.
Hardware Acceleration: Modern hardware often includes specialized processors designed to accelerate neural network operations. These include Graphics Processing Units (GPUs) and Tensor Processing Units (TPUs). Tesla's system identifies and utilizes these accelerators, maximizing performance on the given platform.
Satisfiability
To find the best configuration for a given platform, Tesla employs a "satisfiability solver." This powerful tool, specifically a Satisfiability Modulo Theories (SMT) solver, acts like a sophisticated puzzle-solving engine. It takes the neural network's requirements and the hardware's limitations, expressed as logical formulas, and searches for a solution that satisfies all constraints. Try thinking of it as putting the puzzle pieces together after the borders (constraints) have been established.
Here's how it works, step-by-step:
Define the Problem: The system translates the neural network's needs and the hardware's constraints into a set of logical statements. For example, "the data layout must be NHWC" or "the convolution algorithm must be supported by the GPU."
Search for Solutions: The SMT solver explores the vast space of possible configurations, using logical deduction to eliminate invalid options. It systematically tries different combinations of settings, like adjusting the data layout, selecting algorithms, and enabling hardware acceleration.
Find Valid Configurations: The solver identifies configurations that satisfy all the constraints. These are potential solutions to the "puzzle" of running the neural network efficiently on the given hardware.
Optimization
Finding a working configuration is one thing, but finding the best configuration is the real challenge. This involves optimizing for various performance metrics, such as:
Inference Speed: How quickly the network processes data and makes decisions. This is crucial for real-time applications like FSD.
Power Consumption: The amount of energy used by the network. Optimizing power consumption is essential for extending battery life in electric vehicles and robots.
Memory Usage: The amount of memory required to store the network and its data. Minimizing memory usage is especially important for resource-constrained devices.
Accuracy: Ensuring the network maintains or improves its accuracy on the new platform is paramount for safety and reliability.
Tesla's system evaluates candidate configurations based on these metrics, selecting the one that delivers the best overall performance.
Translation Layer vs Satisfiability Solver
It's important to distinguish between the "translation layer" and the satisfiability solver. The translation layer is the overarching system that manages the entire adaptation process. It includes components that analyze the hardware, define the constraints, and invoke the SMT solver. The solver is a specific tool used by the translation layer to find valid configurations. Think of the translation layer as the conductor of an orchestra and the SMT solver as one of the instruments playing a crucial role in the symphony of AI adaptation.
Simple Terms
Imagine you have a complex recipe (the neural network) and want to cook it in different kitchens (hardware platforms). Some kitchens have a gas stove, others electric; some have a large oven, others a small one. Tesla's system acts like a master chef, adjusting the recipe and techniques to work best in each kitchen, ensuring a delicious meal (efficient AI) no matter the cooking environment.
What Does This Mean?
Now, let’s wrap this all up and put it into context—what does it mean for Tesla? There’s quite a lot, in fact. It means that Tesla is building a translation layer that will be able to adapt FSD for any platform, as long as it meets the minimum constraints.
That means Tesla will be able to rapidly accelerate the deployment of FSD on new platforms while also finding the ideal configurations to maximize both decision-making speed and power efficiency across that range of platforms.
Putting it all together, Tesla is preparing to license FSD, Which is an exciting future. And not just on vehicles - remember that Tesla’s humanoid robot - Optimus - also runs on FSD. FSD itself may be an extremely adaptable vision-based AI.
Subscribe
Subscribe to our newsletter to stay up to date on the latest Tesla news, upcoming features and software updates.
Tesla has just announced the contents and features of its 2025 Spring Update. There’s a lot of new content that we expected, as well as some stuff we didn’t see coming that will be arriving in Tesla’s next major release. Awesome new features, such as Adaptive Matrix High Beams, will finally become available in North America, while others like Grok’s voice assistant aren’t quite ready yet.
So, without further ado, let’s get cracking and take a look at everything in this awesome update.
Adaptive High Beams
The headliner feature of this update is the much-awaited Adaptive High Beams for North America - specifically the United States and Canada. We’ve been waiting a little over a year since it was launched in Europe last year. Tesla faced some regulatory delays in getting this approved, but it’s finally arriving for vehicles with newer headlights.
Adaptive High Beams reduce glare for traffic ahead of you by individually dimming specific pixels on the LED matrix. The feature shipped with the refreshed Model Y first and is now arriving for all other vehicles with matrix headlights. This includes newer Model S, Model 3, Model X, and Model Y vehicles - but not the Cybertruck.
The adaptive headlights in action.
Not a Tesla App
The Cybertruck’s signature headlights are too small to fit the LED matrix, and as such, this feature won’t be supported on the Cybertruck for the time being. Hopefully, Tesla will figure something out, but given that this is a hardware limitation, we don’t expect to see much here.
You can check out our guide on how to determine whether your vehicle is equipped with Matrix Headlights. If your vehicle has the hardware, you will see an Adaptive Headlights option under Controls > Lights > Adaptive Headlights after receiving the Spring Update. This feature will be enabled by default.
Improved Blind Spot Camera for Model S / X
The new blindspot camera in the driver's instrument cluster.
Not a Tesla App
In a surprise addition, Tesla is improving support for the Blind Spot Camera on the 2021+ refreshes of their flagship vehicles. Previously, the blind spot camera on these vehicles would only appear on the primary infotainment screen, not the driver’s instrument panel, which was essentially copied over from the Model 3/Y.
Now, drivers will have the option to choose which display the blind spot camera appears on. A setting under Controls > Display > Automatic Blind Spot Camera will allow drivers to choose “Driver Screen”, so that the blind spot camera appears to the left or right side of the instrument cluster, depending on which turn signal you activate. For these vehicles with an instrument cluster directly in front of the driver, this is a much better implementation of the feature than how it was originally designed.
Dashcam Update - B Pillar Cameras
As part of a much-requested update, given the increased and misguided vandalism against Tesla vehicles, Tesla’s team has finally updated their software to record the B-pillar (upper side) cameras as part of both Dashcam and Sentry Mode.
While this means that Dashcam and Sentry Mode footage will now likely take up more room on your USB drive due to recording two additional cameras, it also means that your vehicle is much better protected. Dashcam and Sentry Mode now record from every camera except for the additional front-facing cameras and the interior camera.
Note: It looks like this feature will be limited to newer vehicles, likely those with AI4.
Improved Dashcam Viewer
The updated dashcam viewer.
Not a Tesla App
The Dashcam Viewer in the vehicle is also being improved with this update. Taking a page from the Tesla app, the app in the vehicle will now display multiple camera feeds at the same time, with users having the option to focus on an individual feed if desired.
Due to the additional cameras being recorded, Tesla is now laying out all the camera feeds along the bottom, instead of at each corner of the screen.
The new UI also reveals that there will be buttons to jump back or forward in 15-second increments, while at the top right, you’ll have a link to the next video, instead of having to go back to the list of videos.
Requirements for Dashcam and Sentry Mode Updates
Unfortunately, there is some bad news regarding compatibility with the B-pillar camera recording and this improved Dashcam Viewer. Tesla says the Dashcam updates will only apply to newer “S3XY” vehicles, but they don’t specify the exact requirement.
Based on previous Tesla posts, where they usually list if a feature requires the AMD Ryzen infotainment processor, this requirement doesn’t sound like an Intel vs AMD issue, but instead one that relies on AI4 hardware, which is responsible for processing the video feeds.
Tesla’s “S3XY” requirement also leaves out the Cybertruck, but this seems like an oversight. Given some previously leaked footage of this feature, we expect the Cybertruck to also receive this feature with the Spring Update.
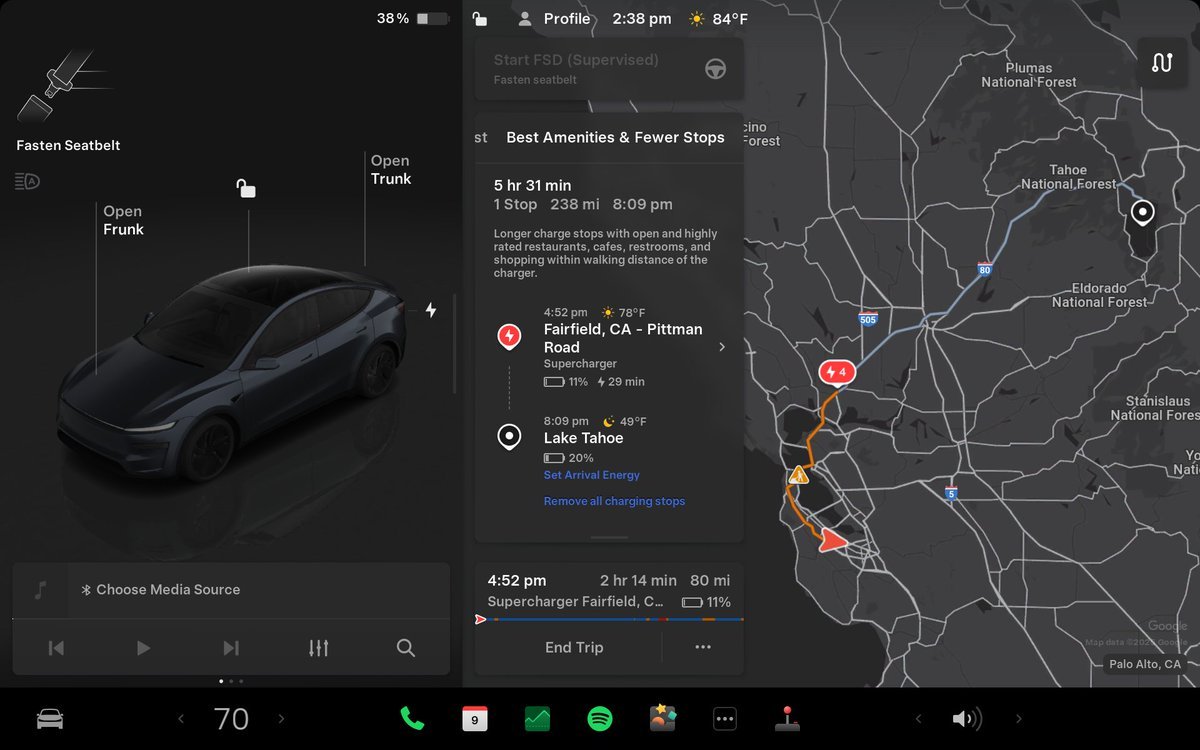
We recently covered routing options on the site, and we believe a lot of people will be pleased with these additions, so if you’ve been craving improved routing options, keep reading.
There are three new routing options to check out. Users will now be able to pick from three types of routing options when choosing a destination. We originally saw these as part of the navigation source code discovered in December 2024.
Fastest: This offers the quickest path to the destination, ignoring any attempts at efficiency or stopping more often to do short charges.
Best Amenities & Fewer Stops:This routing mode minimizes your charge stops in exchange for making them longer, but also allows you to stop near highly rated restaurants, shops, and restrooms for a more relaxing trip.
Avoid Highways: This much-requested feature will enable you to keep your navigation routing away from highways unless they are absolutely required to reach your destination. Hurray for the country roads and relaxed driving.
Requirements: While we’re not sure yet which vehicles will receive these options, we expect it to arrive on all vehicles except for potentially legacy Model S/X.
Trunk Height Based on Location
Another neat and useful little feature: you will now be able to save your trunk opening height based on location rather than applying a general maximum trunk height. If you didn’t already know, you could set the maximum height your automated trunk opens, which can help prevent it from hitting a lower garage ceiling.
This feature is already available on the refreshed Model Y but is now coming to all Model Ys, all Model 3s with automated trunks, and the 2021+ Model S and Model X.
In order to set your height, manually adjust the liftgate to your preferred opening height, and then press and hold the trunk button until you hear a chime in the vehicle, indicating that the height for this location has been set.
Save Frunk Height - Cybertruck
Tesla didn’t forget about the Cybertruck either - you can now do the same with the opening height for the Cybertruck as well. You’ll have to press the exterior (below the bottom center) frunk button and hold it until you hear a chime for the Cybertruck. Pressing the in-frunk button will simply close the frunk.
Accessory Power Option Enables 12V Sockets
Tesla is finally re-enabling 12V accessory power sockets throughout its cars with a new “Accessory Power” option, enabling anyone to use the 12V power sockets in Tesla’s vehicle lineup when they’re away from their vehicle, without needing Camp Mode. This also applies to the USB ports and wireless phone chargers throughout the vehicle.
The Model Y and Model X include a 12V socket in the rear left pillar of the vehicle, alongside a 12V socket in the front of the vehicle. The Model 3 and Model S only have a 12V socket in the front of the vehicle.
You can turn this feature on by going to Controls > Charging > Keep Accessory Power On. This feature is disabled by default and is turned off once the vehicle battery drops to 20% or below. Tesla warns that this feature will use additional power, so it’s best to only use it when needed.
Comfort Drive Mode on the Cybertruck
Following the recent addition of the Comfort Mode option in the Model 3, Tesla is adding the feature to the Cybertruck as well. This feature will automatically switch the vehicle dynamics to “Comfort”, which includes a higher ride height, softer suspension and steering response, and reduction in acceleration profile to Chill Mode while FSD or TACC are active.
You can enable or disable this feature from Controls > Autopilot > Use Comfort Mode in Autopilot. This feature will be enabled by default.
Lane Departure Avoidance on the Cybertruck
Interestingly, the Cybertruck launched without several Autopilot safety and assistance features - namely, because Basic Autopilot itself is missing from the Cybertruck - only FSD and TACC are available. As part of an improvement to safety, Lane Departure Avoidance has now arrived on the Cybertruck with the Spring Update.
This will show a blue indicator on the screen if you begin or are about to begin crossing a lane marking. You will have three options, just like with other Tesla vehicles, including None, Warning, and Assistance. Assistance will provide active feedback and move the vehicle back into the lane lines, while the warning will sound an audio tone and provide visual and physical feedback (vibration) to the steering wheel.
This feature will be enabled by default with Assistance selected and can be changed from Controls > Autopilot > Lane Departure Avoidance.
Minor Updates
Tesla also lists some other smaller details that will be included as part of the 2025 Spring Update, which include these features below:
Keyboard Languages
Go to Controls > Display > Keyboards to switch languages on the touchscreen keyboard.
Media search results are filtered by sources, which provides faster access to your content.
You can now shuffle an entire Apple Music playlist that contains more than 100 songs!
You can scroll through SiriusXM favorites by tapping the left steering wheel button left or right, similar to other services.
You can now sign in to Amazon Music with an Amazon Music Free account. You still require Premium Connectivity or WiFi to stream music.
YouTube Music now shows what song will play next in the Up Next view of the media player.
If you normally connect your vehicle to your phone’s hotspot, this feature will now be enabled every time you drive instead of having you manually connect it each time.
Features We’re Hoping Come Soon
This was an awesome update, but there are always more features we’d love to see come next. Here’s our short list of features we’re still waiting and hoping for.
Everyone’s favorite question is always, When will it be released? Well, it looks like soon. We haven’t seen any vehicles, including employees, receive the Spring Update just yet. However, given that Tesla has officially announced the update, we expect it to go out to employees as soon as this weekend.
Update: Tesla has now started rolling out this update to employees. As expected, it’ll be software update 2025.14.
If no major issues are found, we could see it start rolling out to the lucky first customers in about a week, but be prepared for a slightly longer wait if Tesla needs to reduce multiple revisions of the update before rolling it out publicly.
Tesla’s factories are more than just gigantic locations to produce cars at an insanely fast rate - they’re also locations that live and thrive alongside the environment around them. At Gigafactory Berlin, Tesla planted over 1 million trees in 2024 to help offset the footprint of Giga Berlin. Tesla originally cut down less than half that amount of trees.
One of Tesla’s major goals is to electrify the planet and reduce carbon emissions - and what better way to do that than to create more green space. Tesla has some absolutely fantastic green-centric initiatives, and Giga Berlin really showed that off when they planted double the acreage of forest that they cut down to build the facility.
A rendering of the expected finished locations.
Not a Tesla App
Ecological Paradise
Giga Berlin isn’t the only place that Tesla is working to bring some green to - Giga Texas is also on the list. Tesla has shown off their official renderings and plans for the upcoming Ecological Paradise that will be build around Giga Texas.
Tesla has some absolutely staggering plans for the location, and it's far more than a simple park. With nearly 70,000 residents within 15 minutes of Giga Texas and 15,000 employees commuting into work, there is a considerable number of people to appeal to. That also comes with nearly 4 miles of riverfront - so Tesla will be making the best use of the space to benefit the local community and its employees.
A map of the planned paths, routes, and areas.
Not a Tesla App
The plans for the ecological paradise include a 2-acre riverfront rain garden, as well as 6 rainwater buffer and treatment ponds - all intended to enhance, protect, and expand the 53 acres of local wetland - for a total of 150 million gallons of reclaimed rainwater that will be recycled for landscape irrigation.
Just like green spaces, Tesla places considerable emphasis on water reuse and aims to make its factories as water-neutral as possible. This Ecological Paradise will help to offset the water usage from Giga Texas while also greening up the entire community around it - because all four of the new trailheads, as well as the riverbank, will be publicly accessible.
You can check out the entire filing for the Ecological Paradise, which includes a benefit report to the local community, at this link here. It looks like quite a bit of green space, which will go right alongside the 32,400kW of solar panels installed at Giga Texas - which is the largest single installation of panels in the world.






























![Elon talks about Twitter and job cuts at Bloomberg forum [video]](https://www.notateslaapp.com/images/news/2022/elon-musk-qatar-forum_300w.jpg)